(Information Science Expert) Lecture on Cognitive Robotics
- Also known as Autoencoder
- Encode high-dimensional input X into low-dimensional Features z
- Decode low-dimensional feature z into high-dimensional X’
- The Loss Function of the Neural Network is the difference between x and x’
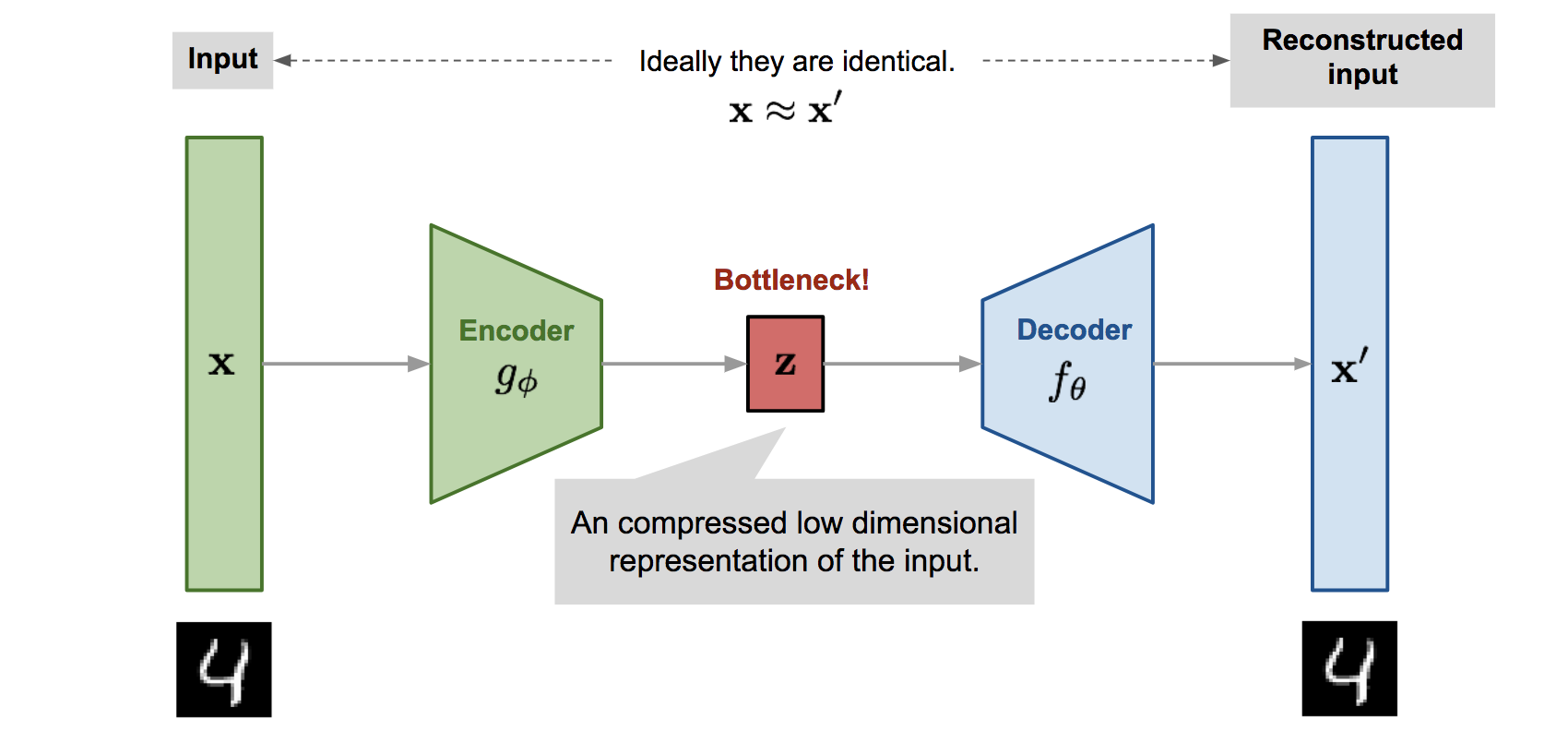
- By changing the decoder to something different from reproducing the same thing, it expands the possibilities
- Called Seq2Seq
- For example:
- For example:
- Encoder: Japanese to low-dimensional
- Decoder: Low-dimensional to English
- —> Machine Translation#natural language processing #Deep Learning