(Information Science Guru) Lecture on Database (NoSQL)
- Is the definition broad/ambiguous?
- 1998: Defined as a term referring to a Data Model that excludes SQL from RDBMS.
- 2009: Defined as a term referring to any Database other than Relational Database.
- New generation of DBMS for Big Data Processing.
- Possesses BASE Characteristics.
- Strengths:
- Handles large data capacity (able to handle massive amounts of data) due to its foundation on distributed systems.
- High scalability (explained in detail under Scalability), as distributed systems follow a “scale-out” model.
- Reduces system management costs by automating tasks such as backups, which were traditionally done by DBAs (administrators). This is because distributed systems inherently require such automated functionality.
- Low infrastructure investment costs.
- Flexible, able to handle various models, including Schemaless and models without Relations.
- Weaknesses (mostly due to its relatively short history):
- Developing system with important features yet to be implemented.
- Lack of support infrastructure, as many systems are open-source and may not receive immediate bug fixes.
- Requires high skill level for system management.
- High programming costs, as it is not as standardized as SQL and requires adaptation to the specific system being used.
- Shortage of experts in the field.
- NoSQL architecture: Distributed Database
- Data Model
- Schemaless
- The minimum unit of data structure: Aggregate (a one-to-one data similar to a tuple).
- Various data models exist (the term “NoSQL” simply means not SQL).
- Key-Value Store (KVS), Document, Column Store, Graph, etc.
- The differences lie in the form of Aggregates.
- Examples:
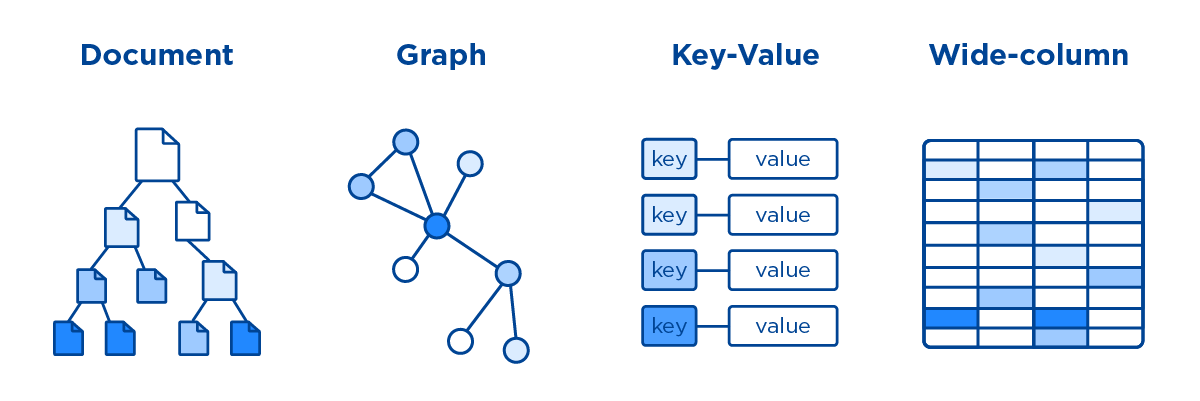
- Key-Value Store (KVS)
- Suitable use cases:
- When information can be uniquely identified by key alone.
- e.g., referencing and updating user information, product information, etc.
- When information can be uniquely identified by key alone.
- Unsuitable use cases:
- When performing set operations on multiple aggregates (key-value pairs).
- When searching based on the value.
- Suitable use cases:
- Document Database
- Supports formats like JSON, XML.
- Semi-structured data that is Schemaless.
- An extension of KVS that allows other aggregates to be placed within the value.
- Allows nesting.
- Suitable use cases:
- When dealing with data with no fixed schema.
- e.g., event logging, blog articles, e-commerce.
- When dealing with data with no fixed schema.
- Unsuitable use cases:
- When performing set operations on multiple aggregates.
- When the data structure changes periodically (why?).
- Column Store
- An intermediate between Document Database and Relational Database.
- Columns exist within rows.
- However, unlike Relational Database, not all rows need to have the same columns.
- Suitable use cases:
- When the schema is mostly the same but occasionally different.
- e.g., event logging, content management systems, blog management systems.
- When the schema is mostly the same but occasionally different.
- Unsuitable use cases:
- When ACID Properties are required.
- When aggregation operations on query results are necessary.
- When dealing with prototypes (where query patterns change frequently).
- Graph Database
- Manages data as a Graph.
- Stores relationships between entities.
- Property Graph: Nodes and edges in the graph have properties (labels, names, etc.).
- Can apply algorithms from Graph Theory.
- Unsuitable use cases:
- When large-scale batch processing is required.
- When dealing with massive graph data.
- Difficult to ensure scalability, as the common approach in NoSQL (dividing and distributing data) is challenging.
- Key-Value Store (KVS)